

开放集语义提取:Grounded-SAM、CLIP 和 DINOv2 流程
链接表
摘要和1 引言
-
相关工作
2.1. 视觉与语言导航
2.2. 语义场景理解和实例分割
2.3. 3D场景重建
-
方法论
3.1. 数据收集
3.2. 从图像中获取开放集语义信息
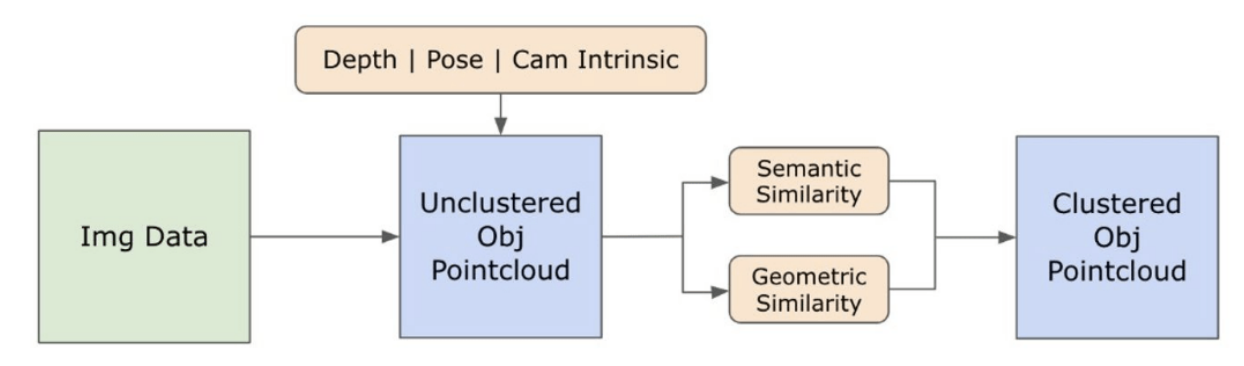
3.3. 创建开放集3D表示
3.4. 语言引导导航
-
实验
4.1. 定量评估
4.2. 定性结果
-
结论和未来工作、披露声明及参考文献
3.2. 从图像中获取开放集语义信息
\ 3.2.1. 开放集语义和实例掩码检测
\ 最近发布的Segment Anything模型(SAM)[21]因其尖端的分割能力而在研究人员和工业实践者中获得了显著的欢迎。然而,SAM倾向于为同一对象生成过多的分割掩码。为解决这个问题,我们在方法论中采用了Grounded-SAM[32]模型。如图2所示,这个过程涉及在三个阶段生成一组掩码。首先,使用Recognizing Anything模型(RAM)[33]创建一组文本标签。随后,使用Grounding DINO模型[25]创建与这些标签对应的边界框。然后将图像和边界框输入到SAM中,为图像中看到的对象生成与类别无关的分割掩码。我们在下面提供了这种方法的详细解释,通过整合来自RAM和Grounding-DINO的语义见解,有效地缓解了过度分割的问题。
\ RAM模型[33]处理输入的RGB图像,为图像中检测到的对象生成语义标签。它是一个强大的图像标记基础模型,展示了在准确识别各种常见类别方面的显著零样本能力。该模型的输出将每个输入图像与描述图像中对象类别的一组标签相关联。该过程首先访问输入图像并将其转换为RGB色彩空间,然后调整大小以适应模型的输入要求,最后将其转换为张量,使其与模型的分析兼容。随后,RAM模型生成标签或标记,描述图像中存在的各种对象或特征。采用过滤过程来精炼生成的标签,这涉及从这些标签中移除不需要的类别。具体来说,诸如"墙"、"地板"、"天花板"和"办公室"等无关标记被丢弃,连同其他被认为对研究背景不必要的预定义类别。此外,这个阶段允许用RAM模型最初未检测到的任何必要类别来增强标签集。最后,所有相关信息被聚合成一个结构化格式。具体来说,每个图像都被编入img_dict字典中,该字典记录了图像的路径以及生成的标签集,从而确保了一个可访问的数据库,用于后续分析。
\ 在用生成的标签标记输入图像后,工作流程通过调用Grounding DINO模型[25]继续进行。该模型专门将文本短语定位到图像中的特定区域,通过边界框有效地描绘目标对象。这个过程识别并在空间上定位图像中的对象,为更细粒度的分析奠定基础。在通过边界框识别和定位对象后,使用Segment Anything Model(SAM)[21]。SAM模型的主要功能是为这些边界框内的对象生成分割掩码。通过这样做,SAM隔离了单个对象,通过有效地将对象从其背景和图像中的其他对象中分离出来,实现了更详细和特定于对象的分析。
\ 此时,对象的实例已被识别、定位和隔离。每个对象都被识别出各种细节,包括边界框坐标、对象的描述性术语、以logits表示的对象存在的可能性或置信度分数,以及分割掩码。此外,每个对象都与CLIP和DINOv2嵌入特征相关联,这些特征的详细信息将在下一小节中阐述。
\ 3.2.2. 语义嵌入提取
\ 为了提高我们对图像中已分割和掩码的对象实例的语义方面的理解,我们使用两个模型,CLIP[9]和DINOv2[10],从每个对象的裁剪图像中派生特征表示。专门用CLIP训练的模型能够实现对图像的强大语义理解,但无法辨别这些图像中的深度和复杂细节。另一方面,DINOv2在深度感知方面表现出色,并且擅长识别图像间的细微像素级关系。作为一个自监督的Vision Transformer,DINOv2可以在不依赖注释数据的情况下提取细微的特征细节,使其在识别图像中的空间关系和层次结构方面特别有效。例如,虽然CLIP模型可能难以区分两把不同颜色的椅子,如红色和绿色,但DINOv2的能力允许清晰地做出这种区分。总之,这些模型捕获了对象的语义和视觉特征,这些特征后来用于3D空间中的相似性比较。
\ 
\ 为了使用DINOv2模型处理图像,实施了一组预处理步骤。这些包括调整大小、中心裁剪、将图像转换为张量,以及标准化由边界框描绘的裁剪图像。然后将处理后的图像与RAM模型识别的标签一起输入到DINOv2模型中,以生成DINOv2嵌入特征。另一方面,在处理CLIP模型时,预处理步骤涉及将裁剪的图像转换为与CLIP兼容的张量格式,然后计算嵌入特征。这些嵌入至关重要,因为它们封装了对象的视觉和语义属性,这对于全面理解场景中的对象至关重要。这些嵌入基于其L2范数进行标准化,这将特征向量调整为标准化的单位长度。这个标准化步骤使不同图像之间的比较保持一致和公平。
\ 在这个阶段的实施阶段,我们遍历数据中的每个图像并执行以下程序:
\ (1) 使用Grounding DINO模型提供的边界框坐标将图像裁剪到感兴趣区域,隔离对象以进行详细分析。
\ (2) 为裁剪的图像生成DINOv2和CLIP嵌入。
\ (3) 最后,将嵌入与上一节的掩码一起存储回来。
\ 完成这些步骤后,我们现在拥有每个对象的详细特征表示,丰富了我们的数据集,以便进一步分析和应用。
\
:::info 作者:
(1) Laksh Nanwani,印度海得拉巴国际信息技术学院;该作者对本工作贡献相同;
(2) Kumaraditya Gupta,印度海得拉巴国际信息技术学院;
(3) Aditya Mathur,印度海得拉巴国际信息技术学院;该作者对本工作贡献相同;
(4) Swayam Agrawal,印度海得拉巴国际信息技术学院;
(5) A.H. Abdul Hafez,土耳其加济安泰普沙欣贝伊哈桑卡利永库大学;
(6) K. Madhava Krishna,印度海得拉巴国际信息技术学院。
:::
:::info 本论文可在arxiv上获取,采用CC by-SA 4.0 Deed(署名-相同方式共享4.0国际)许可证。
:::
\
您可能也会喜欢

那些错过了XRP的人现在将目光投向Apeing ($APEING),视其为2025年有望达到$1的下一个加密货币之一

SEC 发布零售投资者加密货币托管指南
