

SAMBA Proves Hybrid Design Is the Future of Long-Context Modeling
Table of Links
Abstract and 1. Introduction
-
Methodology
-
Experiments and Results
3.1 Language Modeling on vQuality Data
3.2 Exploration on Attention and Linear Recurrence
3.3 Efficient Length Extrapolation
3.4 Long-Context Understanding
-
Analysis
-
Conclusion, Acknowledgement, and References
A. Implementation Details
B. Additional Experiment Results
C. Details of Entropy Measurement
D. Limitations
\
3 Experiments and Results
We pre-train four SAMBA models with different parameter sizes, 421M, 1.3B, 1.7B and 3.8B, to investigate its performance across different scales. The details of the hyperparameters for the training and architecture designs are shown in Table 10 of Appendix A. We also train other hybrid architectures as mentioned in Section 2.1, including the baseline Mamba, Llama-3, and Mistral architecture on a scale of around 1.7B, with detailed hyperparameters in Table 9 of Appendix A. We do comprehensive downstream evaluations on a wide range of benchmarks, focusing on four main capabilities of the models: commonsense reasoning (ARC [CCE+18], PIQA [BZB+20], WinoGrande [SBBC21], SIQA [SRC+19]), language understanding (HellaSwag [ZHB+19], BoolQ [CLC+19], OpenbookQA [MCKS18], SQuAD [RZLL16], MMLU [HBB+21]), truthfulness (TruthfulQA [LHE22]) and math and coding (GSM8K [CKB+21], MBPP [AON+21], HumanEval [CTJ+21]).
3.1 Language Modeling on Textbook Quality Data
We first present results from our largest 3.8B SAMBA model, trained on the same data set used by Phi3 [AJA+24] with 3.2T tokens. We follow the same multi-phase pretraining strategy as Phi3-mini for a fair comparison. We also report the performance of the Transformer++ (TFM++ in Table 1) model, which uses the same architecture and training recipe as Phi3-mini, for a fair comparison.
\ In Table 1, we conduct comprehensive evaluations on a diverse subset of the benchmarks to assess SAMBA’s performance across all the domains mentioned above to ensure a thorough examination of the model’s capabilities. The details of the generation configurations are included in Appendix A.
\ 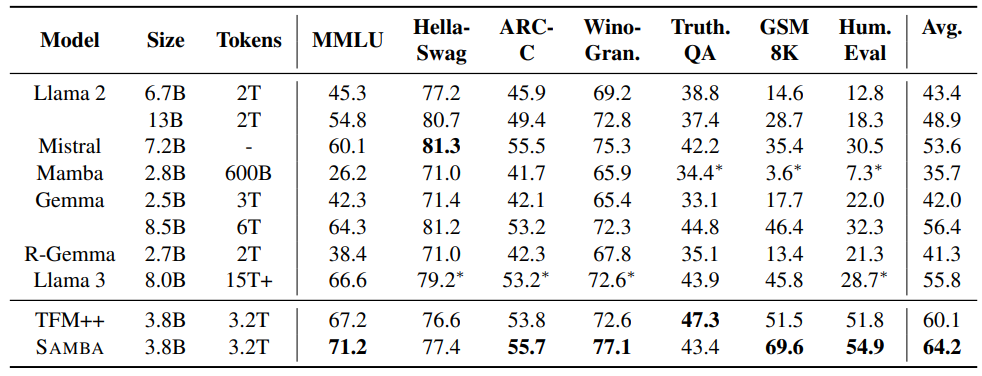
\ We compare with several strong baselines, including Llama 2 [TMS+23], Mistral [JSM+23], Mamba [GD23], Gemma [Tea24], Recurrent-Gemma (R-Gemma) [BDS+24], Llama 3 [Met24] and TFM++. As shown in Table 1, SAMBA achieves the highest average score on all benchmarks, demonstrating its superior performance in handling various language comprehension tasks. Notably, SAMBA excels in the GSM8K benchmark, achieving an absolute 18.1% higher accuracy than TFM++ trained on the same dataset. This shows the surprising complementary effect of combining SSM with the attention mechanism. We conjecture that when combined with attention, Mamba, as an input-dependent SSM, can focus more on performing the arithmetic operation through its recurrent states than on doing the retrieval operation which can be easily learned by the sliding window attention.
\ 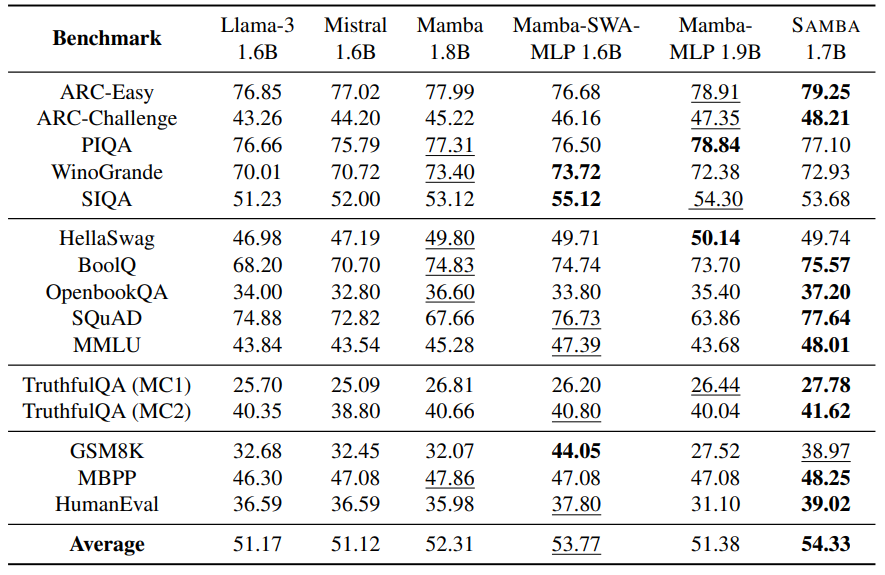
\ To examine the different hybridization strategies mentioned in Section 2.1, we train 6 models with around 1.7B parameters on the Phi2 [LBE+23] dataset with 230B tokens and evaluate them in the full suite of 15 downstream benchmarks to have a holistic assessment of hybrid and purebred architectures. As shown in Table 2, SAMBA demonstrates superior performance on a diverse set of tasks, including commonsense reasoning (ARC-Challenge), language understanding (MMLU, SQuAD), TruthfulQA and code generation (HumanEval, MBPP). It outperforms both the pure attention-based and SSMbased models in most tasks and achieves the best average performance. We can observe that replacing Mamba blocks with MLPs does not harm commonsense reasoning ability, but its performance on language understanding and complex reasoning ability, such as coding and mathematical reasoning, degenerates significantly. We can also see that pure Mamba models fall short on retrieval intensive tasks such as SQuAD due to their lack of precise memory retrieval ability. The best results are achieved through the combination of the attention and Mamba modules, as shown with our Samba architecture. We can also notice that Mamba-SWA-MLP has significantly better performance on GSM8K, potentially resulting from a closer collaboration between the Mamba and the SWA layers. The distinct downstream performances of different hybridization strategies pose interesting future work for developing task-adaptive dynamic architectures.
3.2 Exploration on Attention and Linear Recurrence
Since SSMs belong to a broader realm of linear recurrent models [OSG+23, QYZ23, YWS+23, Kat23, QYS+24], there exist multiple alternatives other than Mamba when combing attentionbased layers with recurrent neural networks. In addition to Mamba and Samba, we investigate the comparative analysis of the following architectures:
\ • Llama-2 [TMS+23] is an attention-based Transformer architecture that utilizes full selfattention across the entire sequence.
\ • Llama-2-SWA is an attention-based architecture that replaces all full attention layers in Llama-2 with sliding window attention.
\ • Sliding RetNet replaces Mamba layers in the Samba architecture with Multi-Scale Retention [SDH+23] layers. RetNet is a linear attention model with fixed and input-independent decay applying to the recurrent hidden states.
\ • Sliding GLA replaces Mamba layers in the Samba architecture with Gated Linear Attention (GLA) [YWS+23]. GLA is a more expressive variant of linear attention with input-dependent gating.
\ 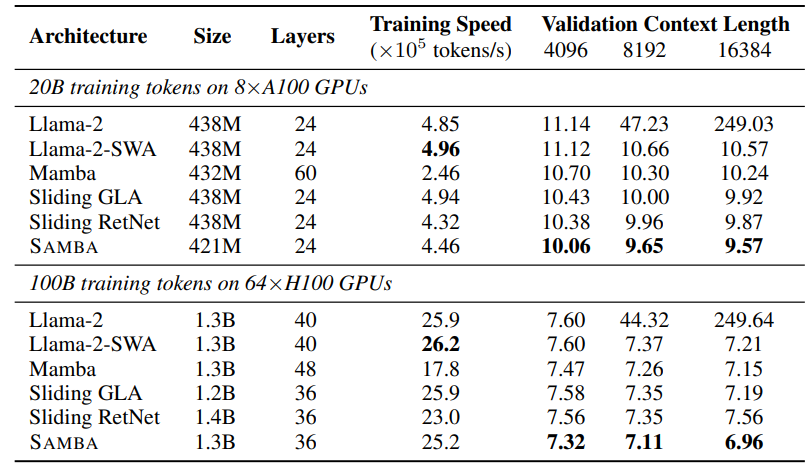
\ We pre-train all models on the same SlimPajama [SAKM+23] dataset under both around 438M and 1.3B settings, and evaluate these models by calculating perplexity on the validation set with context length at 4096, 8192, and 16384 tokens to investigate their zero-shot length extrapolation ability. Peak training throughput is also measured as an efficiency metric. The details of the hyperparameter settings are included in Appendix A. As shown in Table 3, SAMBA consistently outperforms all other models in different context lengths and model sizes. The training speed of SAMBA is competitive compared to pure Transformer-based models on the 1.3B scale. Mamba has significantly worse training throughput because Mamba layers have slower training speed than MLP layers, and the purebred Mamba models need to have more layers than other models at the same number of parameters. We can notice that the full attention-based model cannot extrapolate beyond its context length without specific length extrapolation techniques, which motivates us to use SWA for Samba. In Section 4, we further show that even hybridizing with one full attention layer will still lead to exploding perplexity at 16k sequence length. We can also find that while RetNet can extrapolate well under the 438M scale, it has an increasing perplexity on 16K length at the 1.4B scale, which may indicate that its input-independent decay may need specific tuning at different scales to work well.
3.3 Efficient Length Extrapolation
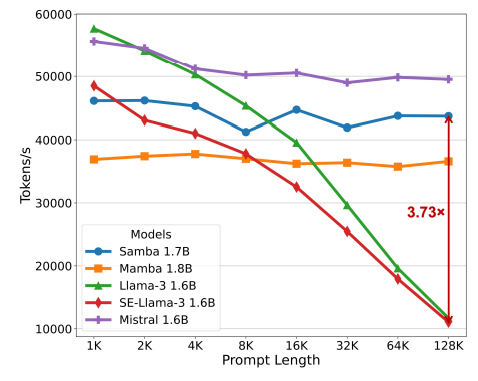
We use the test split of the Proof-Pile [ZAP22] dataset to evaluate the length extrapolation ability of our models at a scale of around 1.7B parameters. We follow Position Interpolation [CWCT23] for data pre-processing. The sliding window approach [PSL21] is used for the perplexity evaluation with a window size of 4096. Besides having the decoding throughput in Figure 1 for the generation efficiency metric, we also measure the prompt processing speed in Figure 3 for the models SAMBA 1.7B, Mistral 1.6B, Mamba 1.8B, Llama-3 1.6B and its Self-Extended [JHY+24] version SE-Llama-3 1.6B with the prompt length sweeping from 1K to 128K. We set the group size to 4 and the neighborhood window to 1024 for self-extension. We fix the total processing tokens per measurement to be 128K and varying the batch size accordingly. The throughput is measured on a single A100 GPU with the precision of bfloat16. We repeat the measurements 10 times and report the averaged results. We can see that Samba achieves 3.73× higher throughput in prompt processing compared to Llama-3 1.6B at the 128K prompt length, and the processing time remains linear with respect to the sequence length. We can also observe that the existing zero-shot length extrapolation technique introduces significant inference latency overhead on the full-attention counterpart, while it still cannot extrapolate infinitely with perplexity performance comparable to that of Samba. In Figure 1, we can also see that Mamba has a slowly and stably increasing perplexity up to 1M sequence length, which indicates that linear recurrent models can still not extrapolate infinitely if the context length is extremely large.
\ 
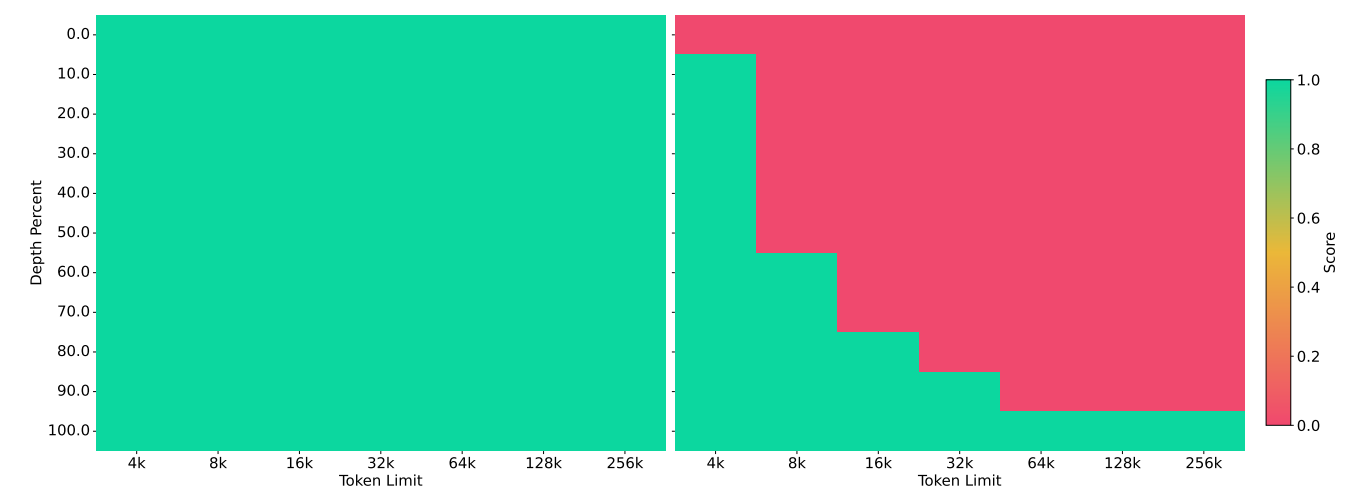
\ Beyond its efficiency in processing long context, Samba can also extrapolate its memory recall ability to 256K context length through supervised fine-tuning, and still keeps its linear computation complexity. We fine-tune Samba 1.7B on Passkey Retrieval with a 4K training sequence length for only 500 steps. As presented in Figure 4, SAMBA 1.7B demonstrates a remarkable ability to recall information from significantly longer contexts compared to Mistral 1.6B, a model based solely on Sliding Window Attention (SWA). This capability is particularly evident in the heatmap, where SAMBA maintains the perfect retrieval performance across a wider range of pass-key positions in a long document of up to 256K length. We also draw the training loss curve and the overall passkey retrieval accuracy across the fine-tuning procedure in Figure 6 and Figure 7 of Appendix B. We find that despite the fact that both architectures can reach near-zero training loss in less than 250 steps, Samba can achieve near-perfect retrieval early at 150 training steps, while the Mistral architecture struggles at around 30% accuracy throughout the training process. This shows that Samba can have better long-range retrieval ability than SWA due to the input selection mechanism introduced by the Mamba layers.
3.4 Long-Context Understanding
The impressive results on the synthetic passkey retrieval task encourage us to perform full-cycle instruction tuning of the Samba-3.8B model. We follow the same post-training recipe used for the Phi-3-mini series and evaluate the downstream performance of the instruction-tuned Samba3.8B-IT (preview) on both the long-context summarization tasks (GovReport [HCP+21], SQuALITY [WPC+22]) and the main shortcontext benchmarks (MMLU, GSM8K, HumanEval), as shown in Table 4. We can see that Samba has substantially better performance than Phi-3-mini-4k-instruct on both the short-context (MMLU, GSM8K, HumanEval) and longcontext (GovReport) tasks, while still having the 2048 window size of its SWA layer and maintaining the linear complexity for efficient processing of long documents.
\ 
\ ![ble 4: Downstream performance comparison between instruction-tuned Samba 3.8B and Phi-3- mini-4K on both long-context and short-context tasks. We report 5-shot accuracy (averaged by category) for MMLU, 8-shot CoT [WWS+22] for GSM8K, 0-shot pass@1 for HumanEval, ROUGEL for both GovReport and SQuALITY. † Results from the Phi-3 technical report [AJA+24].](https://cdn.hackernoon.com/images/null-ai134jo.png)
\
:::info Authors:
(1) Liliang Ren, Microsoft and University of Illinois at Urbana-Champaign (liliangren@microsoft.com);
(2) Yang Liu†, Microsoft (yaliu10@microsoft.com);
(3) Yadong Lu†, Microsoft (yadonglu@microsoft.com);
(4) Yelong Shen, Microsoft (yelong.shen@microsoft.com);
(5) Chen Liang, Microsoft (chenliang1@microsoft.com);
(6) Weizhu Chen, Microsoft (wzchen@microsoft.com).
:::
:::info This paper is available on arxiv under CC BY 4.0 license.
:::
\
You May Also Like

US Spot ETH ETFs Witness Remarkable $244M Inflow Surge

First Ethereum Treasury Firm Sells ETH For Buybacks: Death Spiral Incoming?

