

PerSense Delivers Expert-Level Instance Recognition Without Any Training
Table of Links
Abstract and 1. Introduction
-
Related Work
-
Method
3.1 Class-label Extraction and Exemplar Selection for FSOC
3.2 Instance Detection Module (IDM) and 3.3 Point Prompt Selection Module (PPSM)
3.4 Feedback Mechanism
-
New Dataset (PerSense-D)
-
Experiments
-
Conclusion and References
A. Appendix
\
3 Method
We introduce PerSense, a training-free and model-agnostic one-shot framework designed for personalized instance segmentation in dense images (Figure 3). Here, we describe the core components of our PerSense framework, including Class-label extraction using vision-language model (VLM) and exemplar selection for few-shot object counter (FSOC) (sec. 3.1), instance detection module (IDM) (sec. 3.2), point-prompt selection module (PPSM) (sec. 3.3), and the feedback mechanism (sec. 3.4).
3.1 Class-label Extraction and Exemplar Selection for FSOC
PerSense operates as a one-shot framework, wherein a support set is utilized to guide the personalized segmentation of an object in the query image that shares semantic similarity with the support object. Initially, input masking is applied to the support image using the coarse support mask to isolate the object of interest. The resulting input masked image is fed into the VLM with a custom prompt, "Name the object in the image?". The VLM generates a description of the object in the image, from which the noun is extracted, representing the class-label or the object’s name. Subsequently, the grounding detector is prompted with this class-label to facilitate personalized object detection in the query image. To enhance the prompt, we prefixed the term "all" with the class-label.
\ 
\ Next, we begin by computing the similarity score between query and support features coming from the encoder. Utilizing this score along with detections from the grounding object detector, we extract the positive location prior. Specifically, we identify the bounding box with the highest detection confidence and proceed to locate the pixel-precise point with the maximum similarity score within this bounding box. This identified point serves as the positive location prior, which is subsequently fed to the decoder for segmentation. Additionally, we extract the bounding box surrounding the segmentation mask of the object. This process effectively refines the original bounding box provided by the grounding detector. The refined bounding box is then forwarded as an exemplar to the FSOC for generation of Density Map (DM).
3.2 Instance Detection Module (IDM)
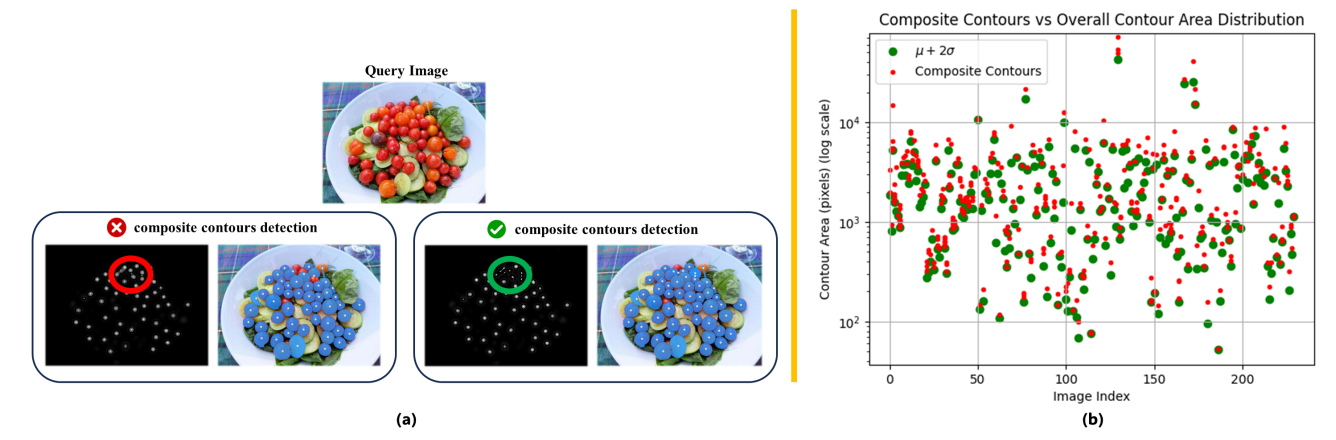
The IDM begins by converting the DM from FSOC into a grayscale image, followed by the creation of a binary image using a pixel-level threshold of 30 (range 0 to 255). Morphological erosion operation using a 3 x 3 kernel is then applied to refine the boundaries and eliminate noise from the binary image. We deliberately used a small kernel to avoid damaging the original densities of true positives. Next, contours are identified in the eroded binary image, and for each contour, its area and center pixel coordinates are computed. The algorithm calculates the mean (µ) and standard deviation (σ) of all contour areas to assess the distribution of contour sizes. Subsequently, composite contours, which represent multiple objects in one contour, are detected using a threshold based on the distribution of contour sizes. This is necessary to identify the regions which are detected as one contour but they encapsulate multiple instances of the object of interest (Figure 4a). Such regions are scarce and can be detected as outliers, essentially falling beyond µ + 2σ considering the contour size distribution (Figure 4b). For each detected composite contour, distance transform is applied to expose child contours for ease of detection. Finally, the algorithm returns the center points obtained from all detected contours (parent and child) as candidate point prompts. In summary, through systematic analysis of the DM, IDM identifies regions of interest and generates candidate point prompts, which are subsequently forwarded to PPSM for final selection. See Appendix A.1 for pseudo-code of IDM.
3.3 Point Prompt Selection Module (PPSM)
The PPSM serves as a critical component in the PerSense pipeline, tasked with filtering candidate point prompts for final selection. For each candidate point prompt received from IDM, we compare the corresponding query-support similarity score using an adaptive threshold as:
\ 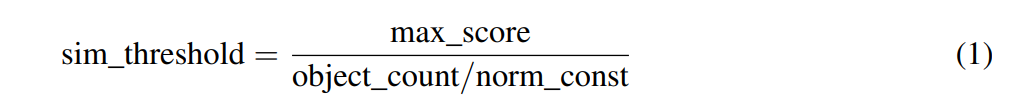
\ where maxscore is the maximum value of query-support similarity score, the objectcount corresponds to the number of instances of the desired object present in the query image and the normconst is a normalization factor to make the threshold adaptive with reference to the object count. We used a normalization factor of √ 2. A fixed similarity threshold would struggle in this case as query-support similarity score varies significantly even with small intra-class variations. Moreover, for highly crowded images (objectcount > 50), the similarity score for positive location priors can vary widely, necessitating an adaptive threshold that accounts for the density (count) of the query image. To address this challenge, our adaptive threshold is based on the maximum query-support similarity score as well as the object count within the query image. In addition to this, PPSM leverages the complementary bounding box information from the grounding detector and ensures that the filtered point prompt lies within the bounding box coordinates. Finally, the selected point prompts are fed to the decoder for segmentation. See Appendix A.1 for pseudo-code of PPSM.
3.4 Feedback Mechanism
PerSense also incorporates a feedback mechanism to enhance the exemplar selection process for FSOC by leveraging the initial segmentation output from the decoder. Based on the mask scores provided by SAM, the top four candidates, from the initial segmentation output, are selected and forwarded as exemplars to FSOC in a feedback manner. This leads to improved accuracy of the DM and consequently enhances the segmentation performance. The quantitative analysis of this aspect is further discussed in sec. 5, which explicitly highlights the value added by the feedback mechanism. See Appendix A.1 for the overall pseudo-code of PerSense.
\
:::info Authors:
(1) Muhammad Ibraheem Siddiqui, Department of Computer Vision, Mohamed bin Zayed University of AI, Abu Dhabi (muhammad.siddiqui@mbzuai.ac.ae);
(2) Muhammad Umer Sheikh, Department of Computer Vision, Mohamed bin Zayed University of AI, Abu Dhabi;
(3) Hassan Abid, Department of Computer Vision, Mohamed bin Zayed University of AI, Abu Dhabi;
(4) Muhammad Haris Khan, Department of Computer Vision, Mohamed bin Zayed University of AI, Abu Dhabi.
:::
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 Deed (Attribution-Noncommercial-Sharelike 4.0 International) license.
:::
\
You May Also Like

Stablecoin News: Visa CEO Confirms Plans to Add Four New Stablecoins

Analysis: The mini-alt market is experiencing a temporary cooling-off, with market preferences returning to Bitcoin.
