

Greenland Gambit Sparks Crypto Chaos: Tariff Threats Send Bitcoin Sliding – Analysts Eye $75K
Markets convulsed after President Donald Trump threatened steep tariffs on eight European nations unless Denmark cedes Greenland, with rhetoric including hints the U.S. might seize the territory by force, triggering a global risk-off move on January 20.
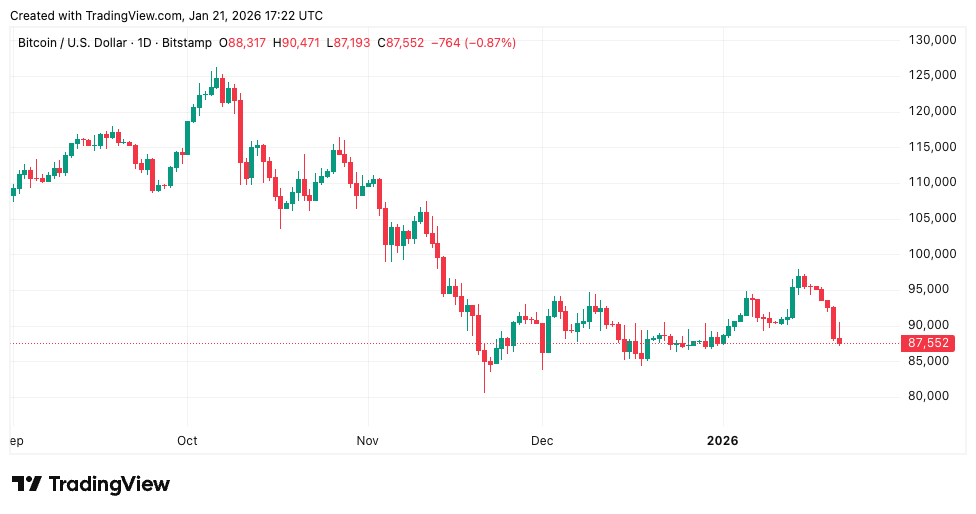
Gold surged to record highs while Bitcoin plunged into the low-$90K range, with some intraday trades dipping as low as $87K.
 Source: TradingView
Source: TradingView
The crypto market shed nearly $150 billion in market capitalization as leveraged positions unwound violently, exposing Bitcoin’s continued treatment as a speculative asset rather than the safe haven its proponents claim it to be.
Tariff Shock Drives Historic Divergence
Trump’s Saturday announcement targeted Germany, France, the UK, the Netherlands, Finland, Sweden, Norway, and Denmark with 10% tariffs starting February 1, escalating to 25% by June 1, unless a Greenland deal is reached.
ING economists warned that “additional tariffs of 25% would probably shave 0.2 percentage points off European GDP growth,” compounding recession fears already gripping the continent.
The tariff threat effectively reopened the trade war between the EU and the U.S., despite a temporary truce reached in late July, raising the stakes and bringing a far tougher approach.
European officials brought forward the option of activating the so-called anti-coercion instrument, the EU’s trade “bazooka“, allowing the bloc to impose tariffs and investment limits on offending nations.
French President Emmanuel Macron announced he would request the instrument’s activation, while Manfred Weber from the European Parliament’s largest party indicated the July deal was now “on ice.”
European countries hold approximately $8 trillion in U.S. bonds and stocks, making Europe by far the largest U.S. lender and exposing the deep interdependence that could turn this standoff into a full-blown crisis.
Germany’s export-reliant economy faces particularly acute pressure, with ING economist Carsten Brzeski warning the new tariffs would be “absolute poison” for the fragile recovery underway.
German exports to the United States fell 9.4% from January to November compared with a year earlier, and the trade surplus dropped to its lowest level since 2021.
Meanwhile, gold’s parabolic rally pushed prices past $4,800 per ounce to all-time highs.
TD Securities’ Daniel Ghali told Bloomberg that “gold’s rally is about trust. For now, trust has bent, but hasn’t broken. If it breaks, momentum will persist for longer.“
Crypto Markets Suffer Violent Unwind
Bitcoin’s collapse alongside traditional risk assets exposed the crypto’s failure to serve as a geopolitical hedge, despite years of positioning as “digital gold.”
CoinGlass liquidation data revealed $998.33 million in long positions wiped out over 24 hours, with Bitcoin accounting for $440.19 million as cascading margin calls accelerated during thin Asian trading hours.
Galaxy Digital’s Alex Thorn noted that “Bitcoin isn’t quite doing the thing that it’s built to do, at least in real time,” while Bitunix analyst Dean Chen observed that “among crypto-native investors, it is increasingly framed as a geopolitical hedge and a non-sovereign store of value.”
“However, for the broader market, Bitcoin is still largely traded as a high-beta risk asset,” he concluded.
Derivatives markets paint an increasingly bearish picture for the months ahead.
Sean Dawson of Derive.xyz warned that “rising geopolitical tensions between the US and Europe—particularly around Greenland—raise the risk of a regime shift back into a higher-volatility environment, a dynamic not currently reflected in spot prices.”
Options data shows strong put open interest concentrated across the $75K-$85K strikes for the June 26 expiry, with Dawson noting that “from an options perspective, the outlook remains mildly bearish through mid-year. Traders are paying a premium for downside protection.“
Bloomberg Intelligence strategist Mike McGlone delivered an even more dire assessment, warning that Bitcoin’s inability to hold long-term averages in 2025 suggests the price could eventually drop as low as $10,000.
Duke University’s Campbell Harvey also claimed in academic research that Bitcoin “is hardly a safe-haven asset,” noting its correlation with gold has broken down completely.
Institutional Demand Offers Potential Floor
Despite the bearish technical picture, not all analysts have turned pessimistic.
MEXC data showed that on January 16 alone, Bitcoin ETFs added 1,474 BTC, accounting for $1.48 billion in weekly inflows, while 36,800 BTC left exchanges.
These are signs of strong institutional demand and tightening supply that could limit downside.
In fact, as Cryptonews noted recently, the chance of Trump turning back on the tariff decision is high, with 86%, and that would greatly benefit Bitcoin after February 1.
Speaking with Cryptonews, Bitfinex analysts also noted that “Bitcoin spot volumes remain normal, funding rates are close to neutral, and there has been no spike in exchange inflows that would signal reactive selling,” suggesting the selloff reflects macro-linked noise rather than a crypto-specific catalyst.
For now, whether Bitcoin’s current consolidation represents capitulation or merely the calm before a deeper storm remains the central question facing crypto markets as February approaches.
You May Also Like

21Shares Launches JitoSOL Staking ETP on Euronext for European Investors

Digital Asset Infrastructure Firm Talos Raises $45M, Valuation Hits $1.5 Billion
